

Research
Our research focuses on microeconometric methods, i.e. on tools for the analysis of individual-level data. A lot of our current research is funded by the ERC Starting Grant "MEImpact".
Measurement error
Measuring economic activity is a fundamental challenge for empirical work in economics. Mismeasurement may lead to severe model misspecification, biased estimates, and misled conclusions and policy decisions. We develop new methodologies for formally assessing the potential impact of measurement error on all aspects of an empirical project: on model-building, on estimation and inference, and on decision-making.
Inference involving ranks
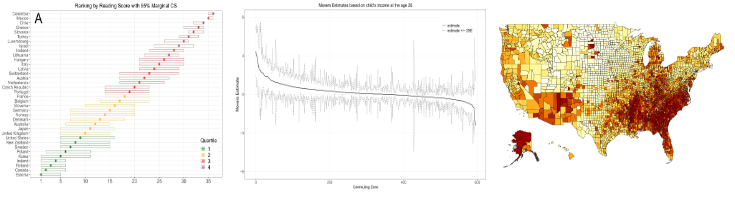
Rankings are often used to succinctly summarize information for subsequent decision-making. For instance, it is common to rank political parties, hospitals, universities, teachers, countries by various measures. We develop methods for assessing the statistical uncertainty in such rankings, which lead to conclusions about how informative an estimated ranking is about the true ranking.
Nonparametric methods for causal inference
We develop new and improve existing methods for inferring causal effects in economic applications. To this end, we leverage classic nonparametric statistical procedures as well as modern machine learning methods. For example, we show that the efficiency of regression discontinuity estimators can be improved by controlling for predetermined covariates in a flexible way and we develop new estimators that can be used when the treatment effect is only partially identified.
Randomization inference
We develop randomization inference methods for testing semi-parametric and nonparametric hypotheses. The focus lies on problems of practical relevance, such as testing for heterogeneity in treatment effects, two-sample testing of a large number of hypotheses, or testing problems under covariate-adaptive randomization. We also develop new algorithms and software implementations to facilitate the adoption of these methods.
Network Data
Network data, which describe the relationships among individuals in a sample, are increasingly available. They form the basis for the analysis of spatial correlations and the understanding of cross-sectional relationships. We develop methods that use network information to improve causal estimates and provide new tools to analyze peer effects.
